Introduction
Vaas is a video analytics system for large-scale video datasets. It provides a web interface that incorporates a query composition tool and data exploration tool to accelerate the development of complex query pipelines. Vaas also provides a human-in-the-loop query optimization framework to accelerate query execution.
Check the quickstart guide or our VLDB 2020 demo video for a quick introduction to Vaas. You can also read our VLDB 2020 demo paper.
Query Composition
The Vaas query composition tool enables users to quickly compose diverse operations to build robust machine learning pipelines that solve complex analytics tasks.
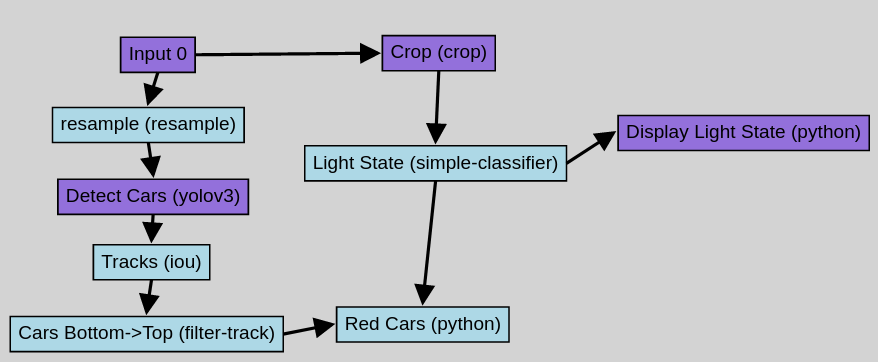
A Vaas query is a directed acyclic graph where data flows from the raw inputs (e.g. a video dataset) to the query's predicate and outputs through vertices that consist of various operations. Each operation transforms its input(s) and produces an output of some type, such as video, object detections, object tracks, or categorical classes.
Besides the graph itself, a query has several additional attributes, including its chunk length, predicate, and outputs.
- The chunk length determines the minimum length of video samples on which the query can be applied. Two examples: if we want to find video frames containing a garbage truck, then we can set the chunk length to 1 frame, since we are interested in individual frames; on the other hand, if we want to find video segments where a car runs a red light, then we may need to set the chunk length to 10 seconds, since we may not be able to tell if there is a car running a red light from just one frame.
- The predicate determines which samples of video should be processed further. If the predicate evaluates false on a sample, then the sample is skipped and outputs are not computed.
- The outputs define which operations in the graph should be displayed to the user. For example, if the output includes both the input video and an object detection model, then Vaas will render the object detections over the video.
The Operations page details the set of operations that Vaas currently supports.
Data Exploration
The data exploration tool is an interactive query execution interface that enables users to efficiently experiment with modifications to a query.
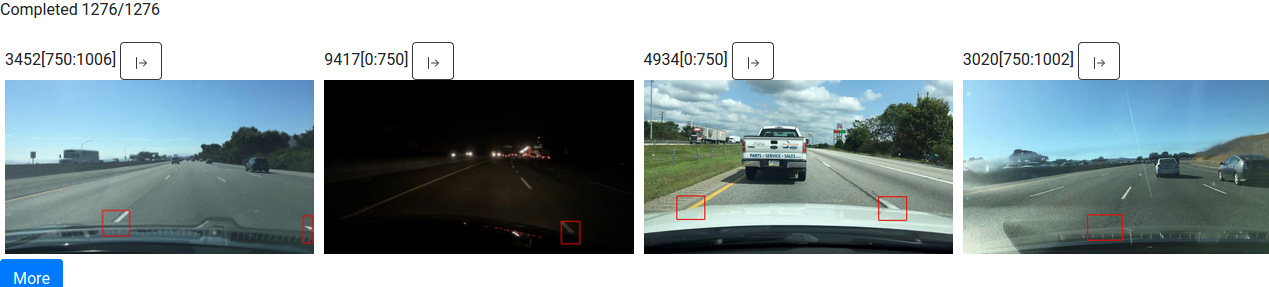
When a query is submitted, Vaas will sample video segments of length equal to the query's chunk length based on the provided sampling settings (i.e., either uniform sampling over the dataset, or sequentially sampling segments starting from some timestamp in a clip). On each sample, it first computes the predicate, and if the predicate evaluates true, it computes the outputs and renders them into a video visualization that is displayed to the user.
Query Optimization
Vaas incorporates automatic optimization suggestions and parameter tuning to accelerate query execution.
Vaas uses a modular framework of optimization suggestion providers that analyze the structure of a query, along with runtime statistics, to automatically propose suggested query modifications. For example, if an object detector is the bottleneck in a query, and is running slower than real-time, then Vaas will suggest to reduce the detector input resolution or the framerate. If a suggestion is accepted, Vaas automatically transforms the query, adding a new tunable operation to the graph.
Several operations in Vaas are tunable, and users can employ the Vaas parameter tuner to select those parameters. Given hand-labeled end-to-end examples and a metric, Vaas will show the user the accuracy of various sets of parameters and their corresponding runtimes.
Data Model
Data in Vaas are represented in a Series. A series is a time series, where some data is associated with each timestep, except the time axis is segmented. For video data, timesteps are video frames, and each segment of the time axis is a different clip or video file in the same video collection.
In Vaas, the overall segmented time axis is a Timeline, and each segment is a Segment of contiguous time.
All data types in Vaas associate data with each timestep. For example, object detections are represented by associating a list of bounding boxes with each timestep.
Vectors are ordered sequences of Series, where the Series are all defined on the same Timeline. Vectors are used in various contexts, e.g. during query execution to define the Series that should be used to provide the query inputs, or when training a model to specify the input data and ground truth labels.
The Data Model page provides more details.